Machine learning in the workplace
There are several common problems with analysing the data routinely collected by companies: measurement error, missing data values or variables, sampling that is non-random or not representative of the population of interest, and the fact that correlation does not necessarily imply causation. These are problems that require careful consideration before implementing a statistical analysis, otherwise the model can provide very misleading answers.
Given the often complex nature of data science and machine learning algorithms, clear and intuitive communication of results to clients is of the utmost importance. In practice, this is sadly an area where data scientist often falter. Part of our duty as data scientists is to not merely create accurate and powerful models, but to also design and package the results from such models in ways that maximise their interpretability and their usefulness to clients. It is also our responsibility to be clear about the limitations of our models and research.
Data science is still an emerging field and there are many buzzwords, like “AI”, “big data”, “machine learning” and “deep learning” that get used, often without any real understanding of what they mean, how they can be implemented, and what their true uses and limitations are. One of the challenges for us is to demystify these terms and clear up misconceptions in order to get people to understand what they mean, and how they are implemented, in practice. One of the common misperceptions about ‘machine learning’ is the idea that the computer or ‘machine’ will uncover patterns and deliver operational insights with little human input. This is definitely not the case – data science and machine learning requires a lot of human thought to identify the question of interest, interpret the results, and to ‘guide’ the machine learning process.
We’ve found that while most firms are good at collecting data, it is very rare that this data is exploited to its full potential. This would often require that someone would need to think creatively about how to use data to persuasively answer important and strategic questions. As data scientists we are able to build algorithms to help companies understand, predict and nudge the behaviour of their clients. To accomplish this task, we need to give due thought to the way that we apply the techniques that are at our disposal, which is often one of the more challenging aspects in our area of work. We have found that by thinking about the particular design of a model in an environment that incorporates individuals with complementary skills, we are able to develop a product that would exceed our individual expectations. In addition, we have also found that by incorporating insights about human behaviour from the social sciences along with recent developments in the quantitative fields, we are able to uncover many useful features that are present in the underlying data.
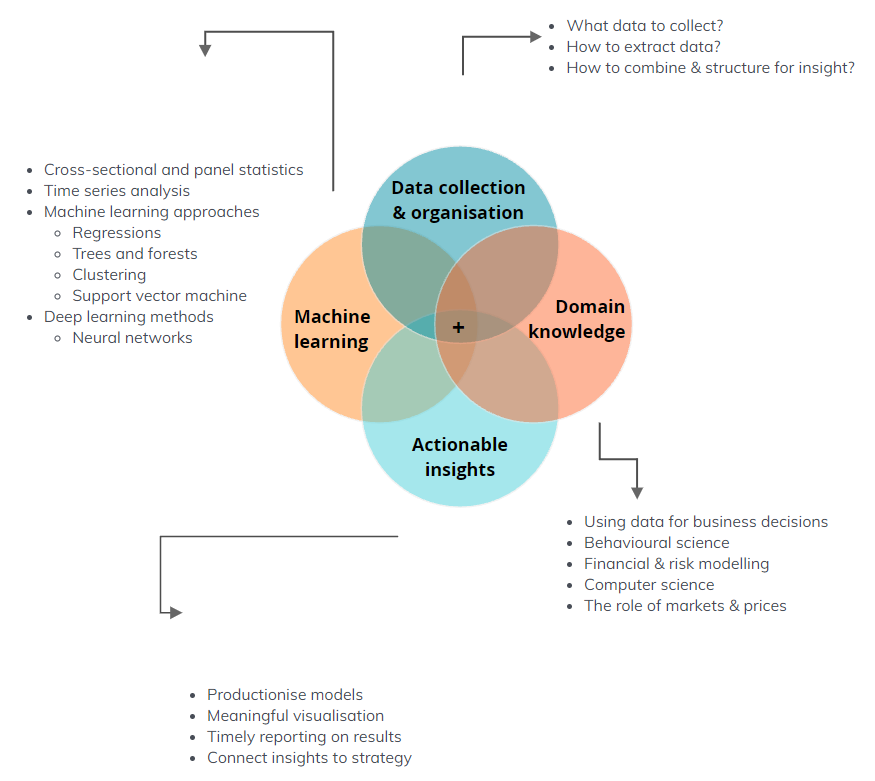
Our Approach
We work with our clients to understand the business problem that needs solving, the information and data they have which can help, and how the solution could fit with their own processes.